
Fastest way
to save 20%
on LLM spend
One API for every major LLM. Built-in caching, smart routing, and enterprise controls - at a lower price than going direct.
One API, every major model
No platform fees
2 minutes to onboard
Built-in caching and routing
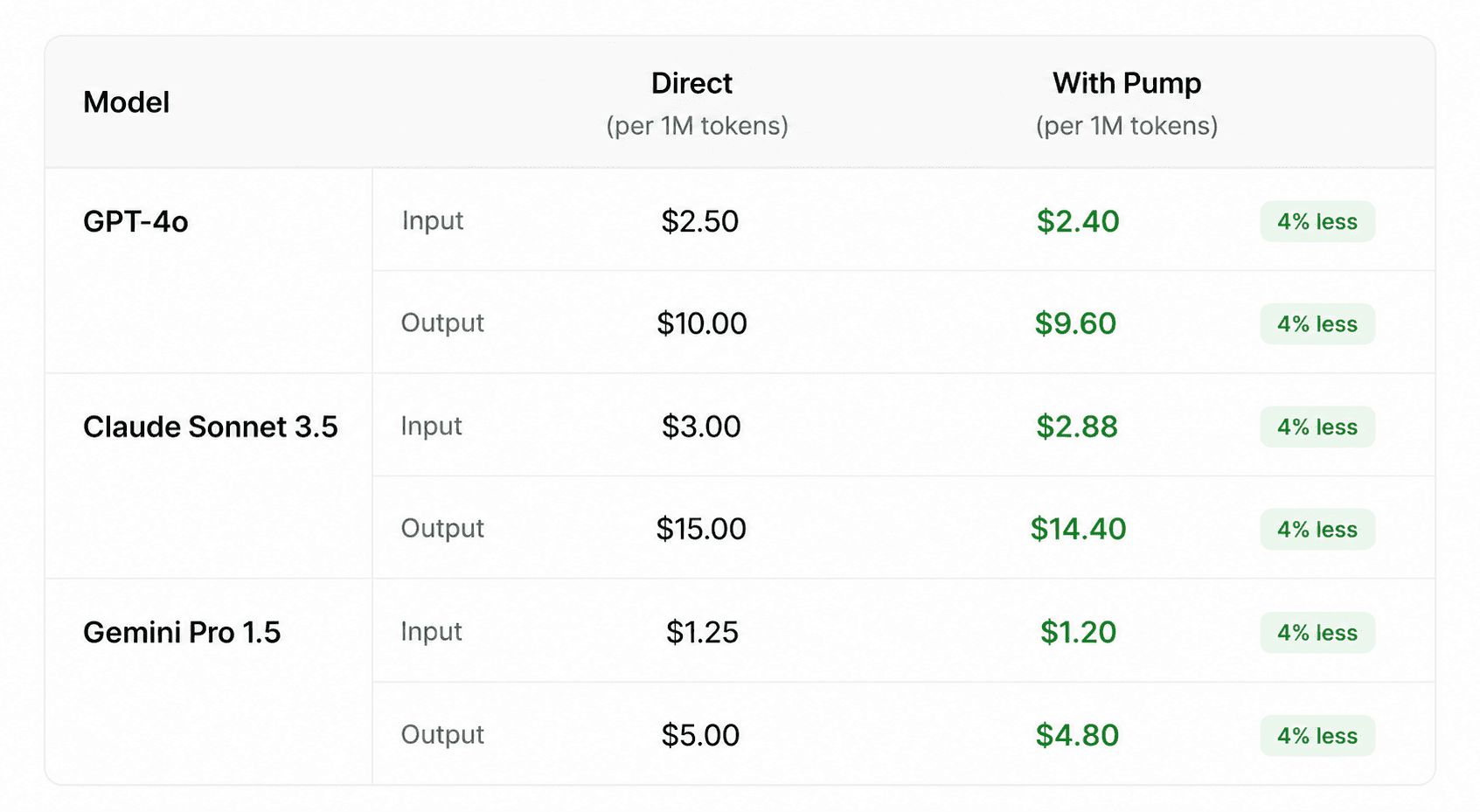
Same models, lower price
One API, every major model
No platform fees
2 minutes to onboard
Built-in caching and routing
Same models, lower price
Supported by over 400+ models

OpenAI

Anthropic

Gemini

Llama

Deepseek

Grok

Mistral

Qwen

Kimi

GLM



Built for teams shipping AI in production


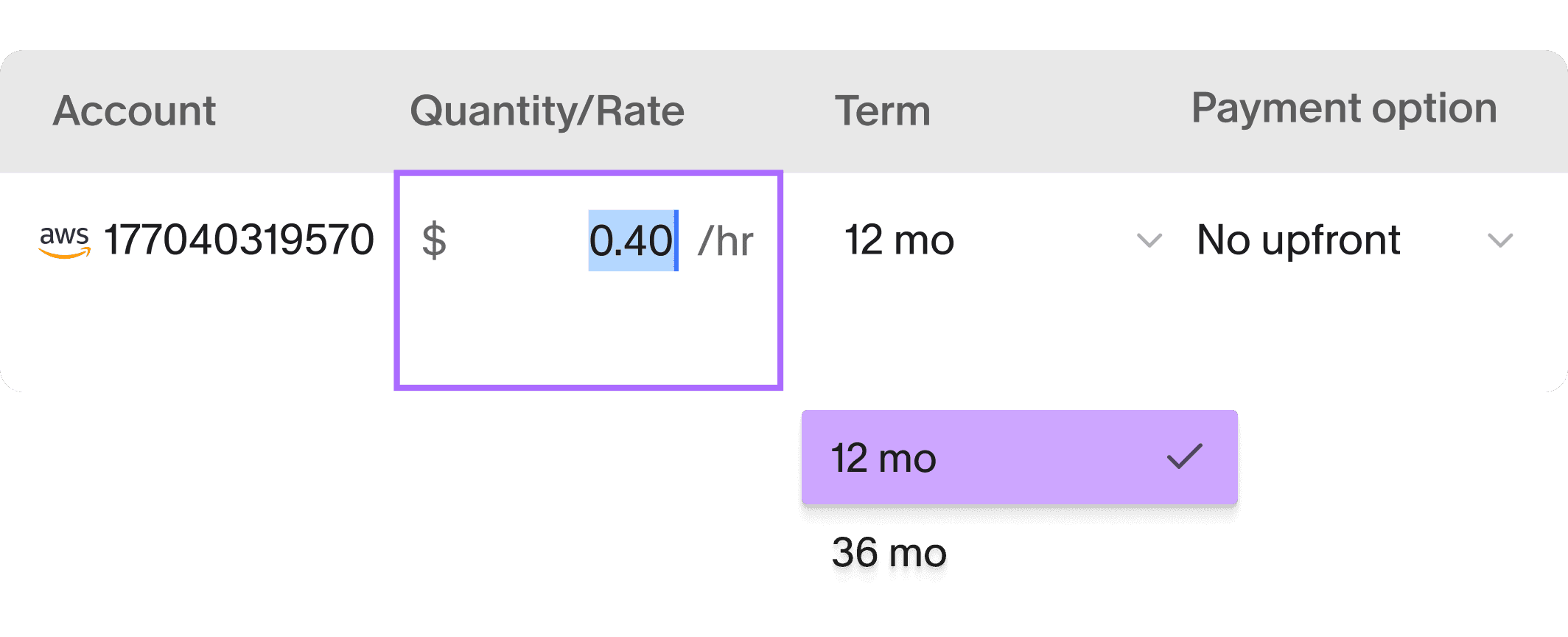
2-COMMITMENT
MANAGEMENT
We sign long-term AWS commitments on your behalf, then dynamically transfer them if your usage changes, so you get the discount without the risk.
Typical savings:
40-60%

1-Commitment
Management
We sign long-term AWS commitments on your behalf, then dynamically transfer them if your usage changes, so you get the discount without the risk.
1-Commitment
Management
We sign long-term AWS commitments on your behalf, then dynamically transfer them if your usage changes, so you get the discount without the risk.
3-INTELLIGENT
RIGHT-SIZING
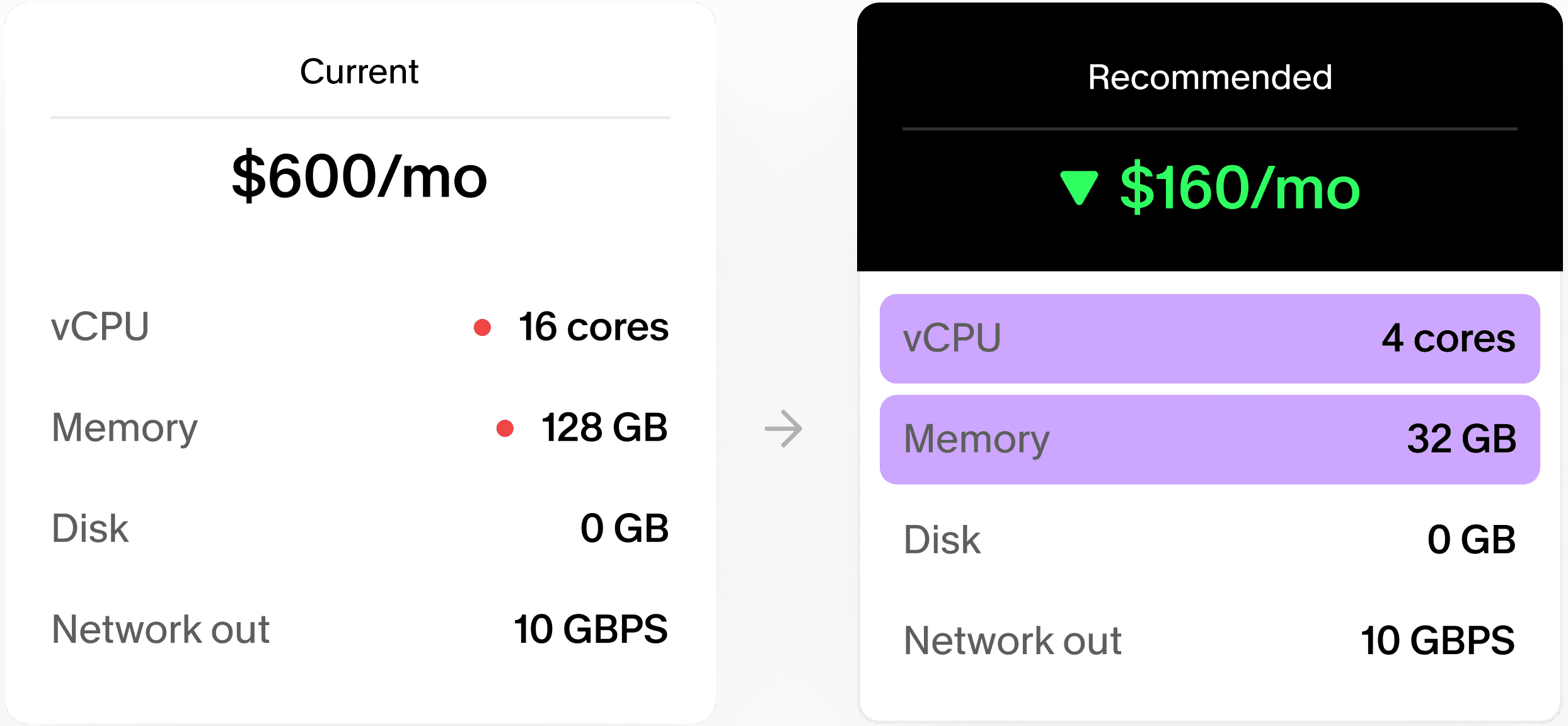
Real-time analysis of CPU, RAM, and traffic patterns tells you exactly when to upgrade (before downtime) or downgrade (to save money).
Typical savings:
30-50%
2-Intelligent
Right-Sizing
Real-time analysis of CPU, RAM, and traffic patterns tells you exactly when to upgrade (before downtime) or downgrade (to save money).
2-Intelligent
Right-Sizing
Real-time analysis of CPU, RAM, and traffic patterns tells you exactly when to upgrade (before downtime) or downgrade (to save money).
NEW
4-KUBERNETES
AUTO-SCALING
For teams using Kubernetes: automatic scaling based on actual demand, spinning resources up and down in real-time.
Typical savings:
45-65%
NEW
3-Kubernetes
Auto-Scaling
For teams using Kubernetes: automatic scaling based on actual demand, spinning resources up and down in real-time.
NEW
3-Kubernetes
Auto-Scaling
For teams using Kubernetes: automatic scaling based on actual demand, spinning resources up and down in real-time.
NEW
5-SPOT
AUTOSCALING POWER
For non-critical workloads, switch to spot and pay 90% less.
Typical savings:
40-60%
NEW
4-Spot
Autoscaling
For non-critical workloads, switch to spot and pay 90% less.
NEW
4-Spot
Autoscaling
For non-critical workloads, switch to spot and pay 90% less.
What commitment
manager does for you
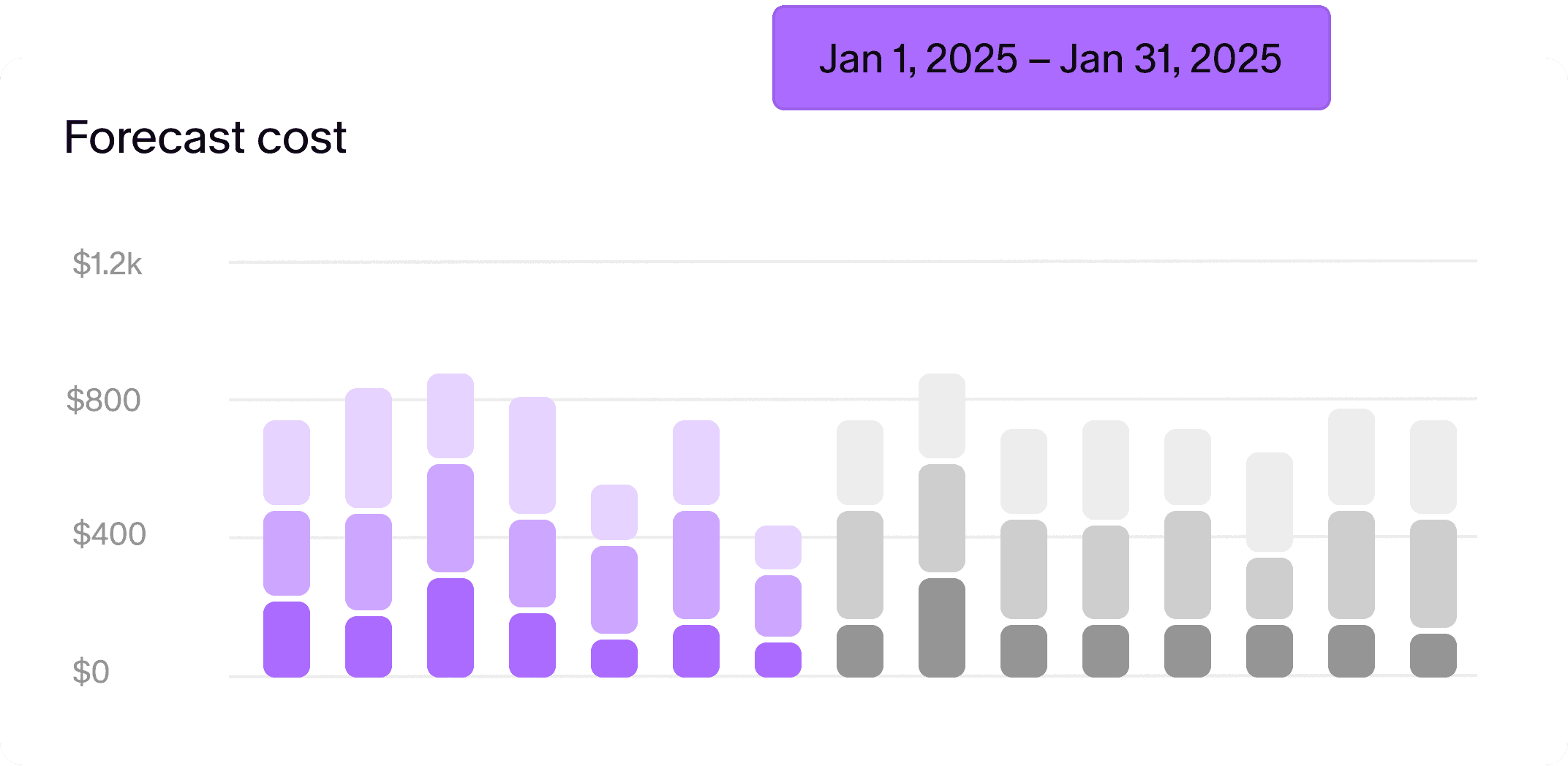
Automated Savings
Baseline Covered with Pump. 100% automated*. Pump analyzes your usage patterns in real-time and purchases optimal plans on your behalf.

Savings
Planner
As we continuously monitor your usage, we surface recommendations that further optimizes savings. Approve with one click or adjust the parameters.
AI Assisted
Recommendations
Pump analyzes your usage patterns and surfaces commitment recommendations sized exactly to your infrastructure, no spreadsheets, no guesswork.
Full Transparency
If your baseline usage ever changes, Pump reimburses you 100% for them. You are not stuck paying for capacity you no longer need. The discount stays locked, but the exposure transfers to us.

Zero markup. Zero platform fees. Here's how.
Pump is an authorized reseller for OpenAI, Anthropic, Google, and other major LLM providers. You get the same models at the same or lower prices. Providers pay Pump a margin for aggregating demand, not you. No credit card, no hidden fees, no catch.
Zero markup. Zero platform fees. Here's how.
Pump is an authorized reseller for OpenAI, Anthropic, Google, and other major LLM providers. You get the same models at the same or lower prices. Providers pay Pump a margin for aggregating demand, not you. No credit card, no hidden fees, no catch.
Zero markup. Zero platform fees. Here's how.
Pump is an authorized reseller for OpenAI, Anthropic, Google, and other major LLM providers. You get the same models at the same or lower prices. Providers pay Pump a margin for aggregating demand, not you. No credit card, no hidden fees, no catch.
Zero markup. Zero platform fees. Here's how.
Pump is an authorized reseller for OpenAI, Anthropic, Google, and other major LLM providers. You get the same models at the same or lower prices. Providers pay Pump a margin for aggregating demand, not you. No credit card, no hidden fees, no catch.
2 mins to onboard
Optimizing what you use today and helping you design what you'll build tomorrow.
BYOK
Grant Pump a read-only permission and view your future savings.
Update Your Base URL
Fully compatible with the OpenAI SDK. Just point your base_url to MixRoute and everything works.
You're All Set!
Switch between GPT, Claude, Gemini, DeepSeek and 400+ models. One key, one bill.
We have answers!
How does Pump make money if there are no platform fees?
Will this add latency to my API calls?
How long does setup take?
What happens if Pump goes down?
Can I keep using my existing provider API keys?
Manage your AI spend in one place
Trusted by 1,000+ engineering teams managing AI in production.
Manage your AI spend in one place
Trusted by 1,000+ engineering teams managing AI in production.
Manage your AI spend in one place
Trusted by 1,000+ engineering teams managing AI in production.
Cloud costs, security, and operations.
One platform.
Cloud costs, security, and operations.
One platform.
Cloud costs, security, and operations.
One platform.
Cloud costs, security, and operations.
One platform.