
Scale your computing tasks seamlessly with the help of AWS Batch, the managed service that removes the burden of server upkeep and job scheduling. Instead of wrestling with provisioning, monitoring, and scaling infrastructure, or worrying about idle servers eating into your budget, you can simply specify the jobs you want to run. AWS Batch then provisions and orchestrates the optimal compute resources, letting you focus solely on delivering insights and making decisions.

This guide provides the insights you need to adopt AWS Batch with confidence. You'll learn the service's architecture and operation, see the functionality that distinguishes it as the go-to choice for organizations of any size, and discover its most productive use scenarios. Each section closes with concrete tactics for keeping your spending under control. Finish the guide, and you'll be ready to use AWS Batch to streamline workflows, minimize management burden, and replace guesswork with predictable results.
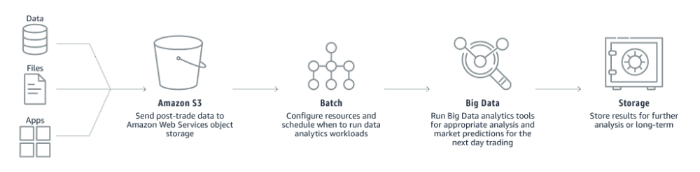
What Is Batch Processing?
(Image Source: AWS Batch)
Before we explore the full capabilities of AWS Batch, we should clarify what batch processing really means. At its core, batch processing is an approach where the computer takes a large number of similar jobs, queues them up, and runs them all at once as a group, or batch. Unlike systems that deal with data the moment it arrives, batch processing waits until the jobs have accumulated and the required computing power is free. This makes it perfect for tasks that don’t need instant responses but require a lot of CPU or memory resources.
Batch processing began with mainframes and has adapted with every leap in technology, ending up in today’s elastic cloud environments. Common applications include:
Data Analytics: Cleansing and summarizing massive datasets for dashboards and trend reports.
Scientific Research: Launching simulations or parsing genomic sequences and chemical simulations at scale.
Machine Learning: Training models on extensive datasets.
Financial Services: Performing risk analysis, transaction processing, and market simulations.
Media Processing: Rendering visual effects, transcoding video files, and automating content delivery pipelines.
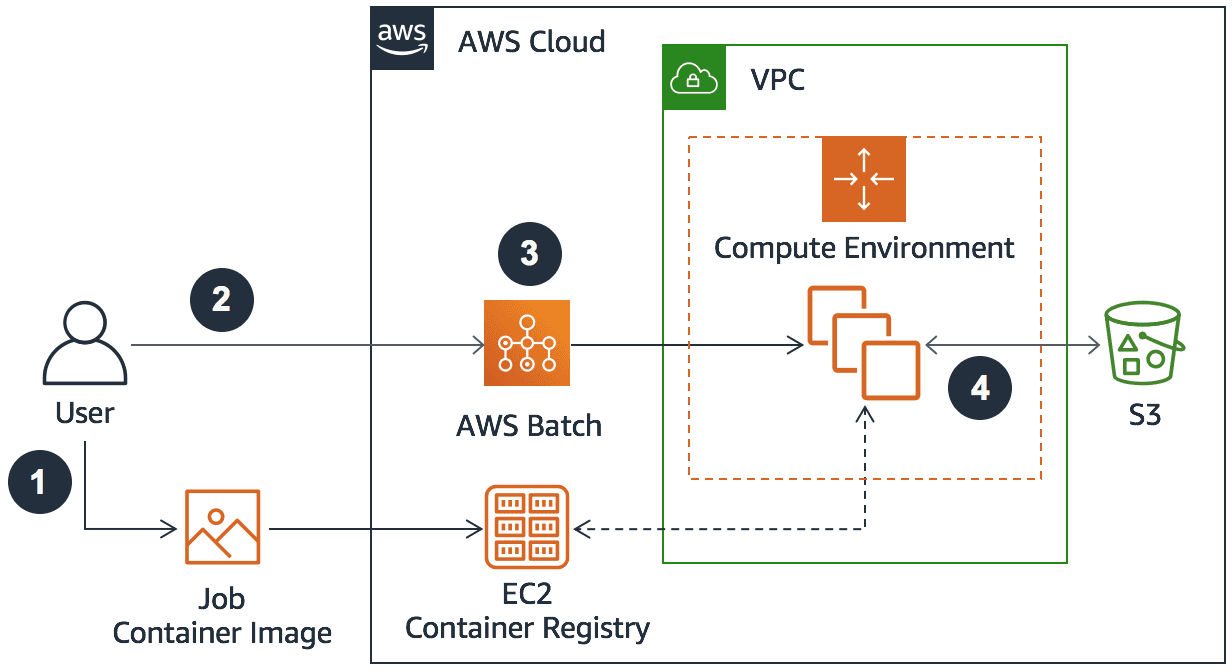
How AWS Batch Works
(Image Source: AWS)
AWS Batch provides a managed framework for running batch workloads, taking care of the underlying infrastructure, scheduling, and scaling. It is built around a containerized ecosystem, employing various AWS compute services to execute jobs. Familiarity with the main architectural components is essential for effective use.
Jobs: Every workload you want AWS Batch to run is a job. This can be a simple script, a complex application, or a self-contained Docker container image.
Job Definitions: A blueprint for your jobs. Definitions map out what a job needs to run: the vCPU and memory it demands, the IAM roles it requires to access resources, and any specific container settings. It’s a reusable template you set once, and jobs inherit it later.
Job Queues: When you submit a job, it lands in a job queue and waits for the scheduler to find a free compute slot. You can set up several queues, each with different priority levels. This layered queue strategy ensures critical tasks get processed sooner without manual intervention.
Compute Environments: These are the compute forests where jobs actually run. A compute environment can be either managed, where AWS Batch handles the provisioning of EC2 instances or Fargate tasks, or unmanaged, if you already want specific resources in your environment. Job instances boot, scale, and terminate based on demand, making it smooth for using on-demand, reserved, or cost-effective Spot pricing.
With AWS Batch, you submit jobs to a managed service that abstracts away the complexities of infrastructure. Just define a job, specify the job definition and the queue, and submit it; the service monitors the queue, dispatches jobs to the right compute resources, and automatically scales the compute clusters up or down to match demand. As jobs run, AWS Batch tracks their state and writes logs to CloudWatch, giving you real-time insight without manual intervention.
Why Use AWS Batch?
AWS Batch delivers a range of compelling advantages for running batch compute workloads, purposefully engineered to abstract the complexities of large-scale data processing so teams can concentrate on the science, not the infrastructure.
Fully Managed Service: With AWS Batch, there’s no requirement to deploy, tune, or maintain a proprietary batch processing stack on server clusters. The service invisibly orchestrates all underlying resources, from node provisioning to real-time scaling and 24/7 monitoring.
Dynamic Scaling and Resource Optimization: AWS Batch automatically evaluates the characteristics of each incoming job to provision the exact mix and quantity of compute resources, CPU, memory, or GPU, required to make the job efficient, eliminating both idle clusters and provisioning delays.
Cost Efficiency: Using both Spot Instances and Fargate Spot, AWS Batch has the potential to cut compute costs by as much as 90% compared to on-demand pricing. Coupled with its clever job ordering and smart placement, idle resources are effectively minimized, permitting you to pay solely for the resources actively engaged with a job. Transparent pricing means you are charged only for the basic AWS infrastructure running the applications, not for a proprietary batch service charge.
Seamless AWS Integration: Being built natively into the AWS ecosystem means you can hook it straight into a larger architecture without extra glue. Integrate into AWS Step Functions for orchestrating the logic; offload datasets to S3 for economical storage; monitor health via CloudWatch metrics; or ring up Lambda for event-driven custom tasks. Together, they give you a unified canvas for constructing batch-oriented, container-driven AWS workflows capable of handling even the most intricate data processing or analytical tasks end to end.
Common Use Cases for AWS Batch
AWS Batch serves multiple sectors with proven workflows that highlight the service's flexibility. Here are some examples:
Scientific Research and High-Performance Computing: Scientists running genomics studies or computational chemistry simulations leverage the service’s support for multi-node parallel processing. By offloading molecular dynamics and large-scale simulations to AWS Batch, teams accelerate analysis and harmonize storage in a single environment.
Financial Services: Banks and financial institutions rely on AWS Batch to run end-of-day risk assessments, generate trade reports, and execute Monte Carlo simulations. By processing these sensitive calculations in a secure, auto-scaling environment, firms meet regulatory deadlines while keeping costs controllable.
Media and Entertainment: Film studios orchestrate batch rendering, media-transcoding, and asset-package delivery to global distributors. By automating these time-consuming steps, teams speed up content pipelines, reduce the risk of human error, and cut on-premises hardware costs.
Machine Learning: Data scientists submit prioritized machine-learning jobs to AWS Batch pipelines. By batching preprocessing, training, and hyperparameter tuning, teams shorten experimentation cycles, track lineage, and optimize compute resource allocation, greatly accelerating the iterative development process.
AWS Batch Pricing and Cost Optimization
AWS Batch pricing reflects only the compute resources your jobs consume; choose from Amazon EC2 (either on-demand, spot, or reserved capacity) or use AWS Fargate under its standard pricing, without any separate fee for the Batch service itself. To scale back your bill, use Spot Instances for jobs that can accept interruptions and fine-tune your compute environments to use resources efficiently.
Best Practices for Cost Optimization
Use Spot Instances: Substantially cut compute costs by setting compute environments to favor Spot Instances whenever jobs can tolerate interruptions. Combine this choice with AWS Batch’s automatic retry submissions to absorb loss of capacity with minimal user effort.
Right-Size Your Jobs: In your job definitions, declare the precise CPU and memory that the application needs, then Batch allocates just that, preventing the waste and cost of over-provisioning.
Fair Share Scheduling: Use the built-in fair-share capability to grant proportional resource quotas to the user and job groups you define. Cost-efficient resource balancing takes place automatically, boosting throughput without over-allocating capacity.
Monitoring and Alerts: Use Amazon CloudWatch to record job and compute environment metrics. Analyze logs for root cause investigations, and configure alarms on cost thresholds and resource utilization metrics to manage dollars in real time..
Retry Policies: Set sensible job retry configurations, such as maximum counts and back-off intervals, so Batch can automatically handle transient failures and conserve human resources.
Auto Scaling: Set minimum and maximum vCPUs in your Batch compute environment to allow Batch to automatically tilt between excess and shortage in the compute environments in a way that marries job throughput to the lowest cost.
Conclusion
AWS Batch provides a highly efficient, scalable, and budget-friendly solution for organizations needing to process a wide range of batch jobs while avoiding the burdens of infrastructure upkeep. By combining container technology, on-demand resource sizing, and tight integration with other AWS services, Batch optimizes throughput and minimizes the work required to keep jobs running. Whether the task is analyzing extensive datasets, training machine learning models, performing scientific simulations, or encoding media, Batch proves to be a solid choice for cloud-native batch processing pipelines. You can start quickly, and built-in cost controls ensure spending stays aligned with usage as workloads grow or contract.
Explore AWS Batch for your batch workloads to fully leverage the capabilities of the AWS cloud.
Join Pump for Free
If you are an early-stage startup that wants to save on cloud costs, use this opportunity. If you are a start-up business owner who wants to cut down the cost of using the cloud, then this is your chance. Pump helps you save up to 60% in cloud costs, and the best thing about it is that it is absolutely free!
Pump provides personalized solutions that allow you to effectively manage and optimize your Azure, GCP and AWS spending. Take complete control over your cloud expenses and ensure that you get the most from what you have invested. Who would pay more when we can save better?
Are you ready to take control of your cloud expenses?




